1 组件
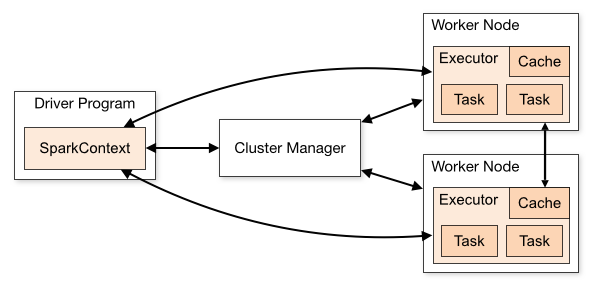
Spark应用在集群中以独立的进程集合运行,通过驱动程序中的SparkContext协作。
SparkContext可以与多种管理器连接。一旦连接,Spark首先获取节点上的用于计算和数据存储的执行器。其次,发送提交给SparkContext的应用代码;最后,SparkContext分发任务给执行器。
注意:
- 应用在各自独立的执行器进程中执行,应用间不能直接进行数据交互。
- Spark对底层管理器不可知,只要能获取执行器进程并交互,可以在一个管理器下运行其他程序。
- 驱动程序需要在程序生命周期中时刻监听并接收来自执行器的连接。因此,驱动节点必须能够被工作节点定位。
- 由于驱动程序调度集群中的任务,因此需要尽可能接近工作节点,通常在同一个本地网络中。如果需要远程请求,可以将驱动程序接近工作节点的环境中,通过RPC连接与驱动联系。
2 管理器类型
- Standalone –简单的,内建的
- Apache Mesos – 可运行MapReduce服务的
- Hadoop YARN – Hadoop 2管理器
- Kubernetes – an open-source system for automating deployment, scaling, and management of containerized applications.开源的,自动部署、扩展和管理容器化应用
此外,第三方管理器Nomad
3 应用提交
详见application submission guide
4 监控
Web UI地址通常为http://<driver-node>:4040。详见monitoring guide
5 作业调度
Spark可以控制应用内和应用间的资源分配,详见job scheduling overview 。
6 术语
